
De Industriële Revoluties
Technologische ontwikkelingen die de maatschappij veranderen zijn niet uniek en lijken zich in een steeds hogere frequentie aan te bieden. De ontwikkeling van de stoom machine in Engeland rond het midden van de 18e eeuw, leidde tot de 1e industriële revolutie waarbij menselijke en dierlijke arbeid werd vervangen door machines. Dit verhoogde de productiviteit en bevorderde de bevolkingsgroei, maar vergrootte ook verschillen in rijkdom en verslechterde de werkomstandigheden (Mohajan, 2019). De 2e industriële revolutie is voortgekomen uit de ontwikkeling van de elektriciteit en resulteerde aan het begin van de 20e eeuw tot de ontwikkeling van massa productie (Melnyk et al., 2019). Deze revolutie creëerde een enorme vraag naar kapitaal en reduceerde veel arbeidsplaatsen door mechanisatie van productieprocessen, maar de verhoogde werkeloosheid werd geabsorbeerd door de bouwsector (Jevons, 1931). Echter werd de angst om banen te verliezen zo groot, dat machines actief gesaboteerd werden tijdens de zogenaamde “Luddite” opstand (Lehman, 2015). De ontwikkeling van halfgeleiders (semiconductors) en de “personal computer” ontketende de 3e industriële revolutie welke de economie heeft gedigitaliseerd (Rosa Righi et al., 2020). In deze periode zien we dezelfde angst en Rifkin (1995) verkondigt zelfs het “einde van arbeid” waarin hij verklaart dat de opkomende kenniseconomie niet voldoende banen zal creëren om de aan automaten verloren arbeidsplaatsen te kunnen vervangen.
Nu, in de 4e industriële revolutie, worden apparaten verbonden aan het internet, data wordt middels machine learning-algoritmen en kunstmatige intelligentie (KI) verwerkt, alomtegenwoordige goedkope sensoren bedden deze technologieën in onze fysieke omgeving in (Philbeck & Davis, 2018). Ondanks de enorme groei van het gebruik van KI, lijkt de productiesnelheid slechts beperkt toe te nemen (hoewel we deze mogelijk onderschatten) of is aanzienlijke vertraagd, mogelijk vindt deze pas plaats wanneer KI zich ontwikkeld heeft tot kunstmatige algemene intelligentie (wanneer KI de menselijke intelligentie evenaart), bekend als de technologische singulariteit (Korinek & Stiglitz, 2018). Ondanks het effect op productiviteit, onderschrijven Korinek en Stiglitz de mogelijkheid dat KI banen gaat vervangen en pleiten ervoor dat economen zich moeten richten op inkomensverdeling. Anderen zijn positiever over de 4e industriële revolutie en verkondigen zelfs dat de 5e zal resulteren in co-existentie van en samenwerking tussen mensen en robots, waarbij de toekomst zich zal richten op duurzaam welzijn (Ziatdinov et al., 2024).
Samenvattend, de vorige industriële revoluties consolideerden macht op basis van verschillende vormen van kapitaal en hoewel ze het algemeen menselijke welzijn hebben bevorderd, vergrootten ze ook de welvaartskloof. Het is niet verrassend dat 7 van de 10 rijkste mensen op aarde, hun rijkdom te danken hebben aan het succes van hun grote technologiebedrijven welke de ontwikkeling van KI het meest stimuleren[1]. Vandaar dat ik verwacht dat dezelfde dynamiek als in de eerdere industriële revoluties, nu ook zal plaatsvinden.
De Hyperreële Economie
Echter, de kenniseconomie gaat niet enkel over werkgelegenheid en productiviteit, deze omvat ook het ontwikkelen van producten en diensten voor kennisintensieve activiteiten in een snel veranderende technologische omgeving (Powell & Snellman, 2004). In plaats van het concentreren op de financiering, implementatie en verkoop van deze op kennis gebaseerde output, beweer ik dat er een belangrijkere dynamiek speelt binnen bij de ontwikkeling van de kennis zelf, welke veel verdergaande gevolgen heeft. Kunstmatige intelligentie welke op grote taalmodellen is gebaseerd (LLM’s) zal de “onwerkelijke economie” transformeren tot een “hyperreële economie”; een economie waarin het onwerkelijke niet meer te onderscheiden is van het werkelijke, ofwel een wereld van zelfreferentiële tekens (Baudrillard, 1988, p. 6).
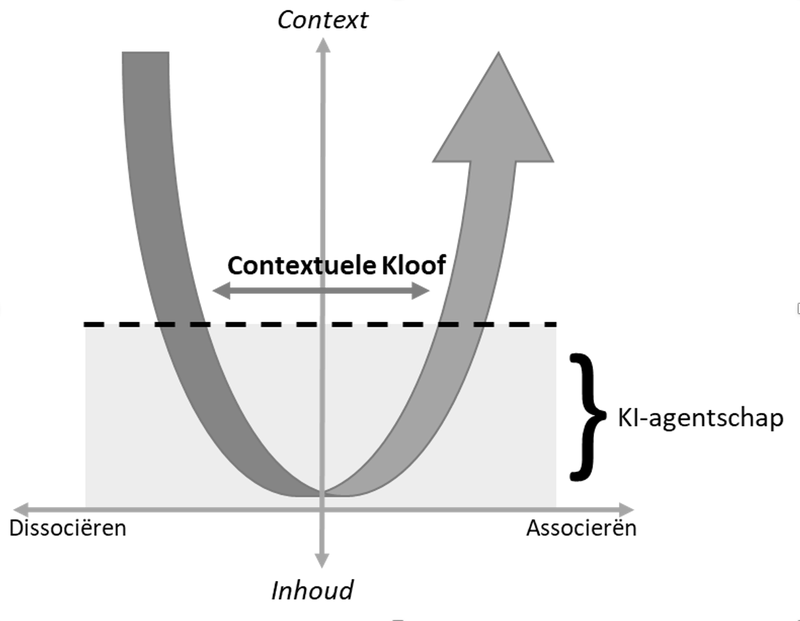
Afbeelding 1: Het effect van KI-agentschap geprojecteerd op het hermeneutische proces waarbij kennis (inhoud) wordt verkregen door de oorspronkelijke context van een tekst te begrijpen (dissociëren) en deze vervolgens in de huidige context te plaatsen (associëren).
Om deze hypothese uit te leggen, moeten we eerst begrijpen hoe we “begrijpen” en hoe de ontwikkeling van grote taalmodellen (LLM-gebaseerde KI) het proces van begripsvorming, de hermeneutische cirkel, beïnvloedt. Volgens de hermeneutiek (de theorie en methodologie van het interpreteren [2]), “kunnen we de delen van een tekst, of een betekenisvol geheel, alleen begrijpen vanuit een algemeen idee van het geheel, maar dit begrip van het geheel is alleen te verkrijgen door de delen te begrijpen” (vertaald uit Grondin, 2015, p. 299). Om een tekst te kunnen begrijpen zullen we deze daarom moeten inbedden in ons wereldbeeld, een proces van associatie (Ricoeur, 2016). Maar om dat te kunnen doen moeten we eerst de echte kennis in de tekst extraheren van de historische context waarin deze is geschreven, een proces van dissociatie. Afbeelding 1 toont dit proces met de gebogen pijl. Het proces van dissociatie vertegenwoordigt van het extraheren van de inhoud uit de historische context (linkerzijde) en associëren is het proces waarin de inhoud in de huidige context wordt geplaatst (rechterzijde).
Wanneer grote taalmodellen (LLMs) teksten verwerken en ons, als eindgebruikers, enkel het resultaat van hun algoritmen tonen zijn we ons niet bewust van “het geheel” dat tot dit resultaat heeft geleid en kunnen we het resultaat enkel als vanzelfsprekend beschouwen. Hierdoor verliezen we ons vermogen om de hermeneutische cirkel te voltooien wat, naar ik betoog, tot een contextuele kloof leidt, wat als een observationele interpretatiefout kan worden beschouwd wat ook wordt gekenmerkt door de uitdrukking “associatie is geen causaliteit” (D’Amico et al., 2025). In andere woorden, hoewel een LLM-algoritme een juist geformuleerde en logische zin heeft geconstrueerd die sterk geassocieerd is met de intentie van de eindgebruiker, de eindgebruiker heeft de inhoud niet volledig gedissocieerd van de context en daarna weer geassocieerd, waardoor deze de tekst niet volledig kan begrijpen. Natuurlijk is voor eenvoudige teksten met weinig historische, politieke en culturele verankering deze contextuele kloof aanzienlijk kleiner of zelfs nihil, maar wanneer de rol van KI in het hermeneutische proces groeit (de horizontale gestreepte lijn in afbeelding 1 verplaatst zich omhoog richting de context), met name voor op KI gebaseerde LLM’s, groeit ook de contextuele kloof. Het gevolg van een grotere contextuele kloof is dat de nieuw verkregen kennis weer door de volgende generatie KI-applicaties wordt gebruikt om (een kunstmatig) contextueel begrip te verkrijgen en wordt daarmee de geobserveerde “realiteit” en hierdoor ontstaat een zichzelf vervullende voorspelling. Ondanks de ontwikkeling van methoden om dit soort fouten te beperken, zoals RAG (Gao et al., 2024), zijn afhankelijk van externe kennisbronnen, ofwel niet kunstmatig gegenereerde inhoud. Wanneer men kan garanderen dat kunstmatig gegenereerde inhoud juist herkend kan worden, blijven we ons bewust van onze contextuele kloof en kunnen we de zogenaamde “model instorting” (Shumailov et al., 2024) voorkomen. Zo niet, dan resulteert de voornoemde vicieuze cirkel in een zelf verwijzend systeem, ofwel de hyperreële economie. Economische beslissingen die invloed uitoefenen op de werkelijkheid zullen worden gemaakt op een zelf versterkte geprojecteerde realiteit, waardoor deze schijn-realiteit uiteindelijk werkelijkheid wordt.
Conclusie
We hebben bekeken hoe eerdere industriële revoluties hebben geleid tot een toename in productiviteit maar ook tot grotere ongelijkheid en verwachten dat dezelfde dynamiek ook nu zal spelen. Vervolgens betogen wij dat grote taalmodellen op basis van kunstmatige intelligentie de opkomende hyperrealiteit zullen voeden door het onderbreken van de hermeneutische cirkel. Terugkomend op de originele vraag naar hoe LLM-gebaseerde kunstmatige intelligentie de kenniseconomie zal beïnvloeden, verwachten wij dat: 1) om kennis bruikbaar te houden, we de contextuele kloof moeten aanpakken en wordt het koppelen van gegevens aan contextuele metadata een cruciaal onderdeel van toekomstige processen voor het vastleggen en beheren van gegevens, 2) om de opkomst van de hyperreële economie te beperken, moet de KI-agentschap zo laag mogelijk blijven en daarom moeten kenniswerkers een systeem creëren dat het niveau van potentiële KI-betrokkenheid valideert, welke LLM gebaseerde systemen in hun algoritmen moet opnemen, en ten slotte 3) blijven creativiteit, kritisch nadenken, en het in twijfel trekken van de geobserveerde realiteit een kerncompetentie voor elke kennis afhankelijke functie. Natuurlijk zijn er andere economische gevolgen van de KI-revolutie, bijvoorbeeld de verwachte verhoging van energie prijzen en koolstofemissies (Bogmans et al., 2025) en niet-economische problemen, zoals het effect van de beperkte representatie van marginale groepen in de samenleving in kunstmatig intelligente systemen (Srivastava & Upadhyay, 2025) welke ook in overweging genomen moeten worden, maar deze vallen voor dit artikel buiten bereik.
Opmerkingen
Voor het schrijven van dit artikel is geen gebruik gemaakt van kunstmatige intelligentie, maar de referenties welke deels uit Google Scholar en WorldCat zijn gedestilleerd, kunnen vooringenomen zijn. De uitspraken in dit artikel zijn uitsluitend de persoonlijke mening van de auteur.
[1] According to Wikipedia https://en.wikipedia.org/wiki/The_World's_Billionaires (September 24, 2025)
[2] According to the American Heritage Dictionary of the English Language (https://www.ahdictionary.com).